What is your investment in Notes applications - revisited

About 2 years ago I asked: " What's your investment in Notes Applications?" and provided steps using DXLMagic to base the answer to that question on evidence rather opinion. With the arrival of version control capabilities in Domino Designer that task became easier (or different - your take). Revisiting the code base I devised new requirements:
Clarification (thx Stefan):
The csv file contains one row per analysed database, with the last column being the Line of Code total for that application. That is the number you fill into the CoCoMo Tool in the New field. Then add Cost per Person-Month (Dollars) and hit Calculate. You get very enlightening results. After that, feel free to play with the settings of the tool.
On its first run the cocomo.jar writes out a properties file that defines what columns go into your csv report file, you can manipulate them as you deem fit. All the other settings are inside the jar, to peak into them, have a look at the source.
When your On Disk Projects are in different places, you can call the app with a 3rd parameter that points to a plain text file that simply lists directory names, one per line to be analysed:
As usual: YMMV
- The analysis should run against the On-Disk-Project rather than the NSF. The simplified assumption here: you deselected the "Use Binary DXL for source control operations"
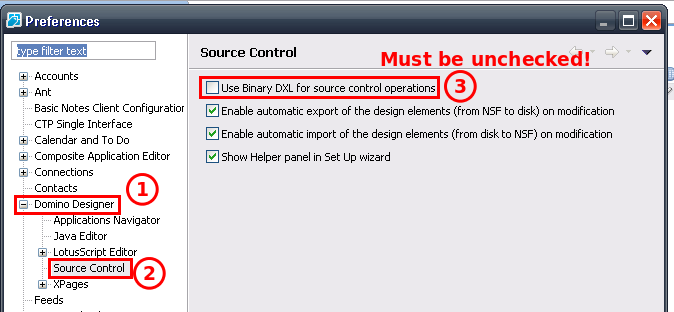
The "binary" format is stored in BASE64, so it wouldn't be impossible to decode, but quite some work to change the parsing, since the tags change too - The analysis code should have no Notes dependencies, so I can run on an Integration Server for continious measurements
- It should be able to analyse a bunch of databases in one go
java -jar cocomo.jar DirectoryAboveYourOnDiskProjects ReportFile.csv.
Clarification (thx Stefan):
DirectoryAboveYourOnDiskProjects is the location where all the directories of your individual On Disk projects are. So if you have C:\ODP\App1, C:\ODP\App2 and C:\ODP\OneMoreApp, you only run the tool once with java -jar cocomo.jar C:\ODP report.csv
The csv file contains one row per analysed database, with the last column being the Line of Code total for that application. That is the number you fill into the CoCoMo Tool in the New field. Then add Cost per Person-Month (Dollars) and hit Calculate. You get very enlightening results. After that, feel free to play with the settings of the tool.
On its first run the cocomo.jar writes out a properties file that defines what columns go into your csv report file, you can manipulate them as you deem fit. All the other settings are inside the jar, to peak into them, have a look at the source.
When your On Disk Projects are in different places, you can call the app with a 3rd parameter that points to a plain text file that simply lists directory names, one per line to be analysed:
java -jar cocomo.jar DirectoryAboveYourOnDiskProjects ReportFile.csv FileWithDirectoryNamesOnePerLine
As usual: YMMV
Posted by Stephan H Wissel on 26 February 2014 | Comments (2) | categories: IBM Notes







{kind=link}