Domino Development - Back to Basics - Part 7: Map Reduce Domino Style

One of the odd things about Domino is the way things are called. It is Memo instead of eMail, Replication instead of Sync, Note store/Document store instead of NoSQL etc. The simple reason is the fact, that all these capabilities predate the more common terms and there was no label for them when Notes had them. In NoSQL circles MapReduce is a hot topic. Introduced by Google, now part of Apache Hadoop it can be found in MongoDB, Apache CouchDB and others. Interestingly it seems that short of Hadoop the mapping doesn't run distributed, but on a single server.
So what about Domino? Holding up the tradition of odd naming, the equivalent of MapReduce is Categorized View where View is the Map component and Categorize is the Reduce capability. The mapping part gets accomplished using the venerable @Formula (pronounced AT-formula) language which got inspired by LISP. If you ever wondered why you had to sort out all "yellow triangles" in kindergarden (a.k.a set theory), once you get started with @Formulas, that knowledge comes in handy. You mainly apply transformations using a set of @functions to lists of values (even a single value is a list, a list with one member). While there is a Loop construct, staying with sets/lists is highly efficient.
In its simplest case a column in a view is simply the name of the Notes item in a document (which will return an empty value if no such item exists). The formulas are used in 2 places: defining the column values of the data that is returned and selecting the documents to be included in the composition of the view. The default selection is
Sorting resulting values is done as a property of the column (second tab in the property box), where sorting is from left to right. In classic Domino you can find views where specific columns are listed twice: once in the position where the user wants to see them, secondly in the sequence needed to sort, but with the attribute "hide this column". In XPages this is no longer necessary, since the view control allows to position columns in a different sequence than the underlying view.
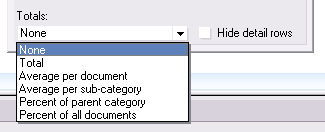
When you categorize a column, typically starting at the first column, Domino offers a set of functions for the other columns to compute reduce values:
You can access the values using
So what about Domino? Holding up the tradition of odd naming, the equivalent of MapReduce is Categorized View where View is the Map component and Categorize is the Reduce capability. The mapping part gets accomplished using the venerable @Formula (pronounced AT-formula) language which got inspired by LISP. If you ever wondered why you had to sort out all "yellow triangles" in kindergarden (a.k.a set theory), once you get started with @Formulas, that knowledge comes in handy. You mainly apply transformations using a set of @functions to lists of values (even a single value is a list, a list with one member). While there is a Loop construct, staying with sets/lists is highly efficient.
In its simplest case a column in a view is simply the name of the Notes item in a document (which will return an empty value if no such item exists). The formulas are used in 2 places: defining the column values of the data that is returned and selecting the documents to be included in the composition of the view. The default selection is
SELECT @All which lists all documents in that database regardless of form used (if any) to create them or items contained in them. This is very different from tables/views in an RDBMS where each line item has the same content. Typically Notes application designers make sure, that all documents share a common set of items, so when combined in a view something useful can be shown. Often these item names are lifted from the mail template: Subject, Categories, From, Body.
Sorting resulting values is done as a property of the column (second tab in the property box), where sorting is from left to right. In classic Domino you can find views where specific columns are listed twice: once in the position where the user wants to see them, secondly in the sequence needed to sort, but with the attribute "hide this column". In XPages this is no longer necessary, since the view control allows to position columns in a different sequence than the underlying view.
When you categorize a column, typically starting at the first column, Domino offers a set of functions for the other columns to compute reduce values:
You can access the values using
?OpenView&CollapseAll in Domino's REST API or in code using a ViewNavigator. A categorized view always starts with a category, so you begin with a .getFirst() followed by .GetNextSibling() for one level categories or .GetNextCategory() if you have multiple levels of categories. This capability helps when you aggregate data for graphics or pivot tables or [insert your idea here]Posted by Stephan H Wissel on 13 February 2014 | Comments (3) | categories: IBM Notes XPages