Picking your routing and replication architecture

Routing and replication is a core function of the Domino server. There are a few basic facts you need to consider when setting them up. A very popular setup, which I quite like too, is a hub spoke architecture: a central spoke communicates with spokes, so any communication has a maximum of 2 hops. An additional advantage of such an architecture is, that a server only needs to "see" the hub to reach any of the other servers. But even for a hub-spoke architecture there is room for improvement. Let us make two assumptions: the hub is where your SMTP mails arrive and depart (so "hub" could be a cluster) and all servers can see each other on the network.
- Mail Routing
The normal Hub-Spoke routing has the advantage, that every email message is delivered with the maximum of 2 hops and that you only need 2 connection documents per server. It also works independent from network architecture or IP ranges.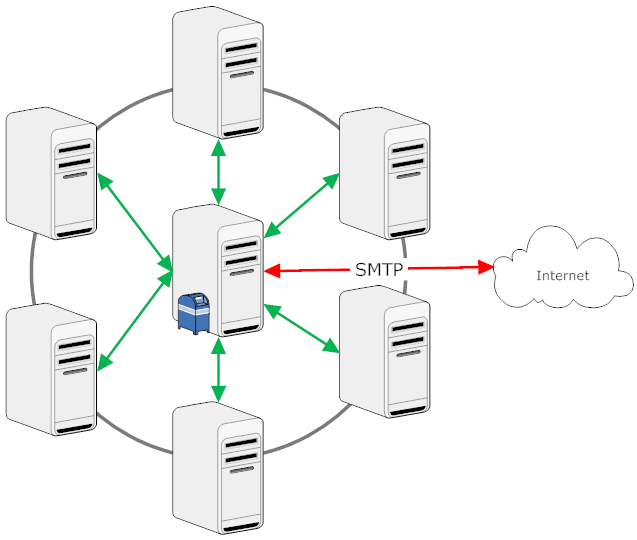
Of course - you need connection documents and every message will use 2 hops. If you have a lot of large internal traffic you create a bottleneck at the hub (even with multiple mailboxes). When all Domino servers "see" each other direct routing will be more efficient. To setup direct routing you need to put all participating Domino server into the same Notes Named Network (which implies that they all share the same network protocol - not an issue with TCP/IP everywhere today). You won't need connection documents anymore and routing is instant and direct.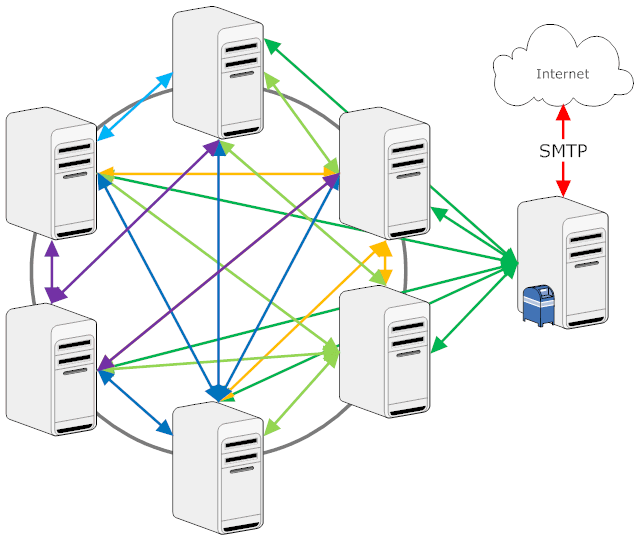
Are there reasons (beside obviously wanting of the prerequisites) why you wouldn't want to use direct routing? When you use your hub to perform central functions like virus scan, content integrity, enterprise archival, compliance check etc. you want every message to pass through your hub. Be careful what you wish for, you might just create your next bottleneck. - Replication
Replication comes with many choices: What server starts it, pull only, push only, pull-pull, pull-push. So it can get a little confusing (should I draw a diagram for you?). Hub Spoke replication architectures make a lot of sense. With 2 cycles all replicas are current. This is especially important for your system documents. However you need to be clear about how you set it up. The typical setup is the hub server to be scheduled to replicate with the spokes. From the 2 options: pull-pull and pull-push we find mostly pull-push. This means the hub does all the work.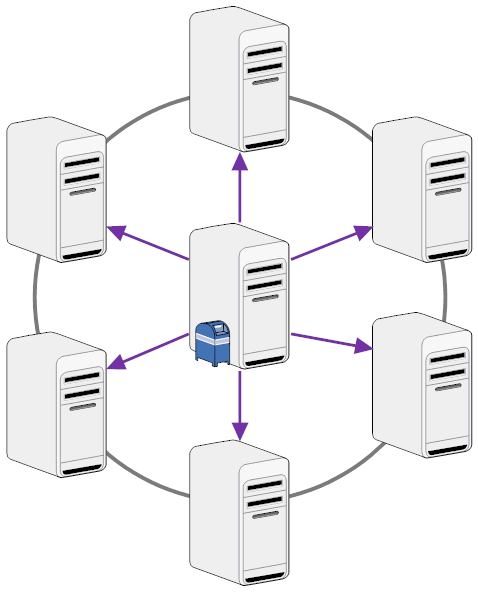
Since the hub doesn't do anything else (eventually run some central agents?), that seems a sensible choice. However it has a large pitfall. By default there is one replicator up and running per server. So your Hub is replicating with one spoke at a time. You can increase that number to 4 but you will with large changeset and many spokes run out of your replication time window. On the other side of a replication there is just another user session (watch your console, you will find: "Session opened for server Hub/MyCorp"). So when you turn the replication direction around it scales much better.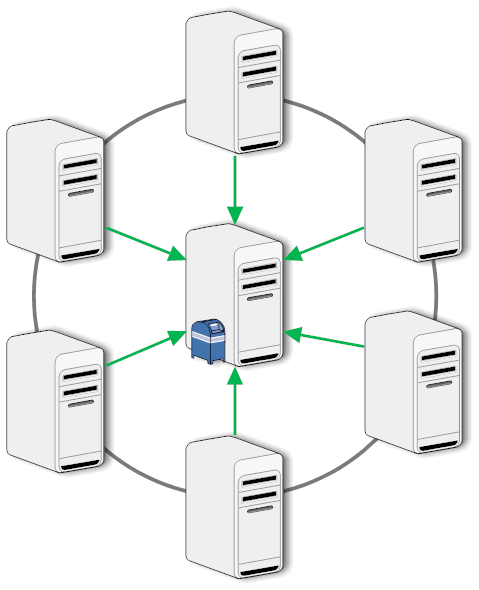
When you schedule a pull-push replication on every hub, you can schedule all replications at the same time, since they are just sessions on the hub. You still will need 2 cycles to have all documents on all servers. Why would you not want to do that? 2 potential reasons (one stronger, one weaker) come to mind: firstly since all spokes push documents to the hub at the same time the peak utilization of the indexer on the hub goes up and might slow down other functions temporarily (time critical agents?); secondly replication is a bit "messier" the spokes might get some of the updated documents already in the first cycle instead of the second, if your application relies on sets of documents (Lotus Workflow comes to my mind) you end up with some documents "missing" until the completion of the second cycle. Other than that Spoke Hub replication is your method of choice.
Posted by Stephan H Wissel on 19 June 2009 | Comments (0) | categories: Show-N-Tell Thursday