NoSQL schema design

A question that pops up frequently in developer discussions is "how to structure your data in a NoSQL way?". To shed a light on this, we have a look at the approach invented 50 years ago and still an all time favorite
Normalization
In a simple order example, we are looking at four tables:
- Customer
- Product
- Order
- OrderEntry
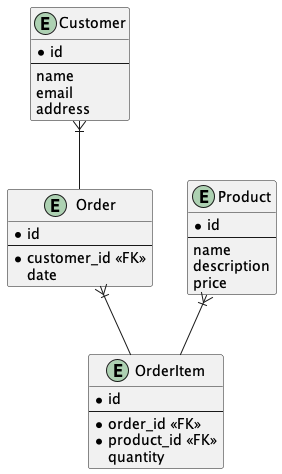
In this design, there are no duplicates and some simple SQL can list out all I need, for example the order value for a given order:
SELECT oi.order_id,
SUM(oi.quantity * p.price) AS order_total
FROM OrderItem oi
JOIN Product p ON oi.product_id = p.id
GROUP BY oi.order_id
WHERE oi.order_id = 67111;
or the revenue per customer:
SELECT c.id AS customer_id,
c.name AS customer_name,
SUM(oi.quantity * p.price) AS revenue
FROM Customer c
JOIN Order o ON c.id = o.customer_id
JOIN OrderItem oi ON o.id = oi.order_id
JOIN Product p ON oi.product_id = p.id
GROUP BY c.id, c.name;
Not so fast
When looking at real diagrams, you will find duplicate information all over:
- The Order table will have an address and a total
- The OrderEntries has a description and a price
The reason is twofold: one is performance (a flat query for the total field runs better than a SUM(..) over a JOIN) and secondly, the seeming redundancy (price in OrderEntry, address in Order) actually isn't redundant, but shows different data:
The base table (Customer, Product) show "value as it is current", while the derived tables (Order, OrderEntry) show "value as it is business actual" or "point-in-time". Your system might have a service to determine a sales price based on many factors, so a JOIN won't do, a customer might move, but the old orders, being a business record, MUST NOT show the new address - that would be altering a legal "document".
Which brings us to the insight:
Business runs on documents, not tables
The NoSQL way
Accnowledging the business nature of point-in-time data a NoSQL document might look like that:
{
"id": 123,
"date": "2019-01-01",
"address": "3rd rock from the sun",
"customer": {
"id": 456,
"name": "John Doe"
},
"items": [
{
"id": 789,
"name": "light saber",
"quantity": 2,
"price": 10.0
},
{
"id": 101,
"name": "Force training manual",
"quantity": 1,
"price": 20.0
}
]
}
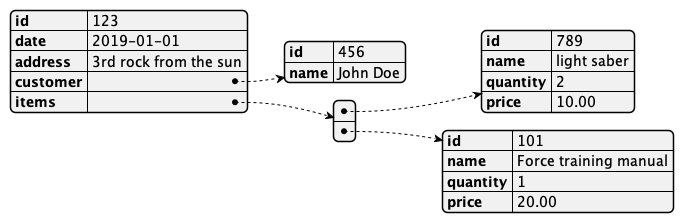
Instead of JOINing tables, information is looked up (Some languages even had a special MOVE CORRESPONDING instruction specifically for that) at creation time.
A business function needs to take care when values in the base information changes (e.g. update all order adresses where the status indicates they are affected).
No light without shadow
SQL, wich is a total misnomer once you look at the INSERT, UPDATE and DELETE statements (or ALTER TABLE for that matter), has the advantage of little fragmentation (PL/SQL, T-SQL) and the ability to pack the business functions into triggers.
In the NoSQL world wheels are reinvented daily: MQL, mango, DQL, JSONPath and more.
So choose your persistance wisely
Posted by Stephan H Wissel on 06 June 2024 | Comments (0) | categories: NoSQL WebDevelopment