Extracting data from Domino into PDF using XSLT and XSL:FO (Part 3)

This entry is part of the series Domino, XSL:FO and XSLT that dives into the use of XSLT and XSL:FO in IBM Lotus Domino.
In Part 2 I introduced the Java code required to output PDF from XSL:FO and how that code can be called from an XAgent. Now lets have a look at XSL:FO itself. It is a W3C defined standard to layout documents. You could consider it as competitor to PostScript or PDF. XSL:FO contains both layout instructions and content. Since it is expressed entirely in XML, it is easy to manipulate (follow me for a moment and accept XML is easy) and - more importantly easy to split content and layout for reuse. Typically a complete XSL:FO document would be only an intermediate step in PDF production. The report design (without data) would be contained in an XSLT stylesheet that gets merged with XML data. You could consider XSLT the "templating language" of XSL:FO.
A XSL:FO document has a single
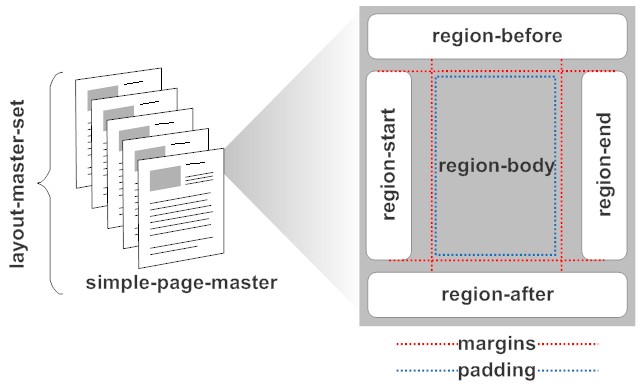
Besides the page size (and content orientation) a simple-page-master defines header, footer, left and right column (called regions). You need to get your math right there. The margin and the regions are both substracted from the page size to compute the real margins. When you have a
The main element region-body allows to specify a column-count attribute that will create multi-column page layouts without the need for a table and a manual calculation of column content. You also could define alternating page masters, like left and right pages or different pages for a chapter beginning - read details in the repeatable-page-master-alternative specification.
Your main content is contained in one or more page-sequences.
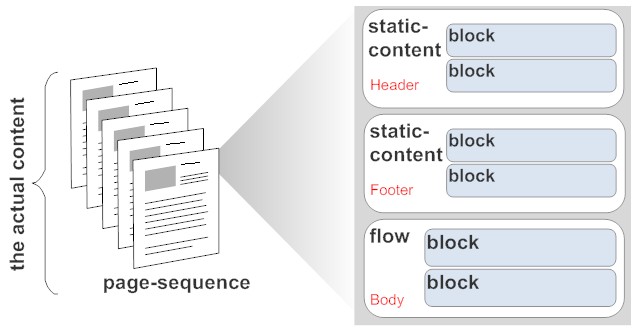
The page sequence contains the content. Don't get confused: a page-sequence represents content of n number of pages (n >=1), not just one page. You need more than one page sequence only when you want the page layout to use a different master/style (of course using the alternatives mechanism described above you can achieve alternate styles inside a single page sequence). The page sequence contains one or more flows. A flow is targeted at a region (there are 5 of them) and contains block elements (think HTML div,p,table etc.) that contain the content. There are a huge number of specialised attributes and elements (stuff like watermarks or graphics) available you can learn about in the specifications.
In practise you write a sample XSL:FO document and transform it into PDF. Once you are satisfied with the results, you then convert the XSL:FO document into an XSLT stylesheet. This is easier than it sounds, you simply wrap (also available on Kindle
(also available on Kindle  ).
).
Next stop: How to pull Notes data into XML for processing.
In Part 2 I introduced the Java code required to output PDF from XSL:FO and how that code can be called from an XAgent. Now lets have a look at XSL:FO itself. It is a W3C defined standard to layout documents. You could consider it as competitor to PostScript or PDF. XSL:FO contains both layout instructions and content. Since it is expressed entirely in XML, it is easy to manipulate (follow me for a moment and accept XML is easy) and - more importantly easy to split content and layout for reuse. Typically a complete XSL:FO document would be only an intermediate step in PDF production. The report design (without data) would be contained in an XSLT stylesheet that gets merged with XML data. You could consider XSLT the "templating language" of XSL:FO.
A XSL:FO document has a single
<fo:root> element. This contains one or more page-sequence elements, that contain the actual content and a layout-master-set, that defines the pages.
Besides the page size (and content orientation) a simple-page-master defines header, footer, left and right column (called regions). You need to get your math right there. The margin and the regions are both substracted from the page size to compute the real margins. When you have a
margin="1cm" and a region-start with 3cm width, then the left margin is 4cm. Read up the XSL:FO tutorial on w3schools.com for more details.
The main element region-body allows to specify a column-count attribute that will create multi-column page layouts without the need for a table and a manual calculation of column content. You also could define alternating page masters, like left and right pages or different pages for a chapter beginning - read details in the repeatable-page-master-alternative specification.
Your main content is contained in one or more page-sequences.
The page sequence contains the content. Don't get confused: a page-sequence represents content of n number of pages (n >=1), not just one page. You need more than one page sequence only when you want the page layout to use a different master/style (of course using the alternatives mechanism described above you can achieve alternate styles inside a single page sequence). The page sequence contains one or more flows. A flow is targeted at a region (there are 5 of them) and contains block elements (think HTML div,p,table etc.) that contain the content. There are a huge number of specialised attributes and elements (stuff like watermarks or graphics) available you can learn about in the specifications.
In practise you write a sample XSL:FO document and transform it into PDF. Once you are satisfied with the results, you then convert the XSL:FO document into an XSLT stylesheet. This is easier than it sounds, you simply wrap
xsl:template tags around your fo and replace your sample content with xsl:apply-templates statements. w3schools has a simple example. Of course XSLT is a interesting topic on its own, go and read the XSLT 2.0 and XPath 2.0 Programmer's Reference Next stop: How to pull Notes data into XML for processing.
Posted by Stephan H Wissel on 28 April 2012 | Comments (2) | categories: Show-N-Tell Thursday XPages